Search Engine, Named Entity Recognition and…
Application
Published on March 9, 2019 by game_of_code_2019_saperlipopette_team

This is a degraded experience of Portail Open Data. Please enable JavaScript and use an up to date browser.

This repository contains Python and R scripts for applying NLP to the XML Dublin Core files that can be downloaded from https://data.bnl.lu/data/historical-newspapers/
The scripts add new features to the data, perform Named Entitity Recognition and also recommend new articles based on cosine similarity of article content.
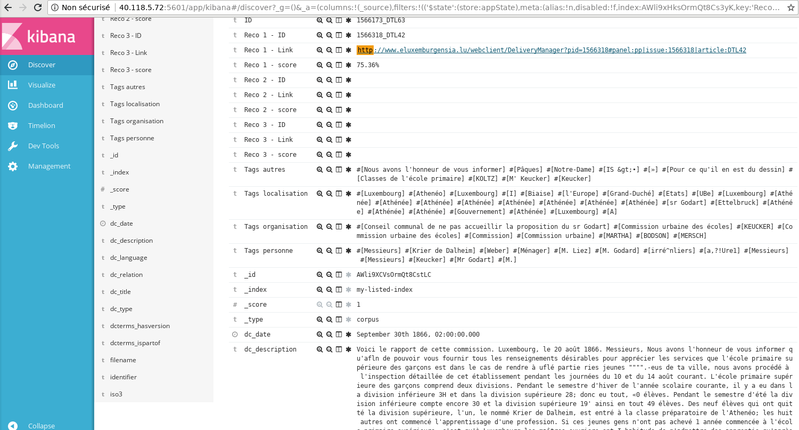
Everything is then deployed into an ELK suite hosted on the cloud. You can find the app here: http://40.118.5.72:5601/app/kibana#/discover?_g=()
The app is an advanced search engine that allows historians to look for keywords and perform basic data analysis on Kibana (visualisations). There are 2 databases; the full one with around half a million articles on which we did not perform cosine similarity for article recommendation, and then a smaller database (around 50.000) on which 3 articles at most get recommended to the user.
We had to limit the computation of cosine similarity because of time constraints.
This organization hasn't published any datasets yet.
Application
Published on March 9, 2019 by game_of_code_2019_saperlipopette_team

July 21, 2025
5c83ec514384b033a0383397
March 9, 2019