Search Engine, Named Entity Recognition and Recommender System on the Historical Newspaper data of the BNL
Publié le 9 mars 2019

game_of_code_2019_saperlipopette_team
This repository contains Python and R scripts for applying NLP to the XML Dublin Core files that can be downloaded from https://data.bnl.lu/data/historical-newspapers/ The scripts add new features to the data, perform Named Entitity Recognition and also recommend new articles based on cosine…
1 réutilisations
Informations
- Type
- Application
- Thématique
- Autres
- ID
- 5c83ed6f4384b033a0383399
Publication
Intégrer sur votre site
URL stable
Description
This repository contains Python and R scripts for applying NLP to the XML Dublin Core files that can be downloaded from https://data.bnl.lu/data/historical-newspapers/
The scripts add new features to the data, perform Named Entitity Recognition and also recommend new articles based on cosine similarity of article content.
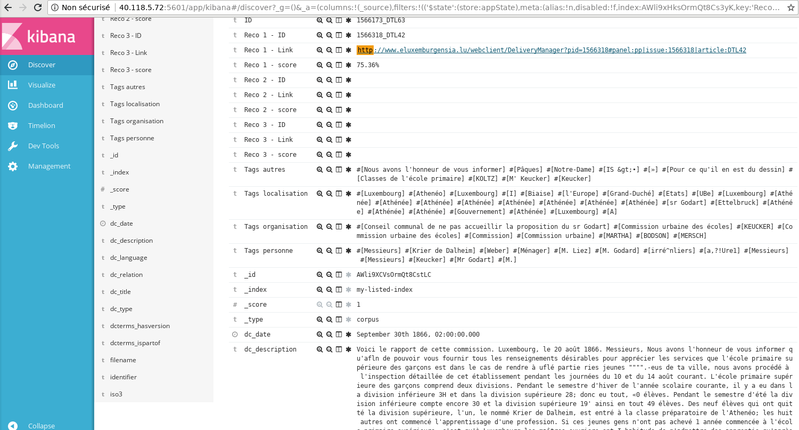
Everything is then deployed into an ELK suite hosted on the cloud. You can find the app here: http://40.118.5.72:5601/app/kibana#/discover?_g=()
The app is an advanced search engine that allows historians to look for keywords and perform basic data analysis on Kibana (visualisations). There are 2 databases; the full one with around half a million articles on which we did not perform cosine similarity for article recommendation, and then a smaller database (around 50.000) on which 3 articles at most get recommended to the user.
We had to limit the computation of cosine similarity because of time constraints.
Jeux de données utilisés 1
Discussion entre l'organisation et la communauté à propos de cette réutilisation.
Plus de réutilisations
Découvrez davantage de réutilisations.
-

-
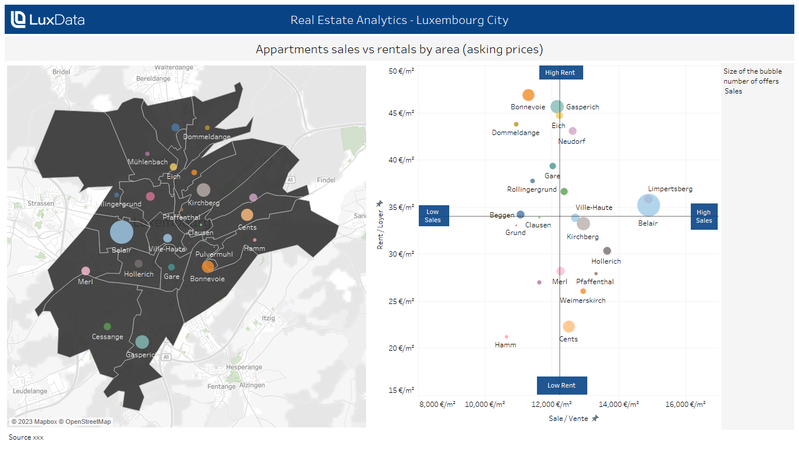
Apartment sales vs rentals by neighbourhood (asking…
Visualisation
Publié le 19 avril 2024 par LuxData
-
-
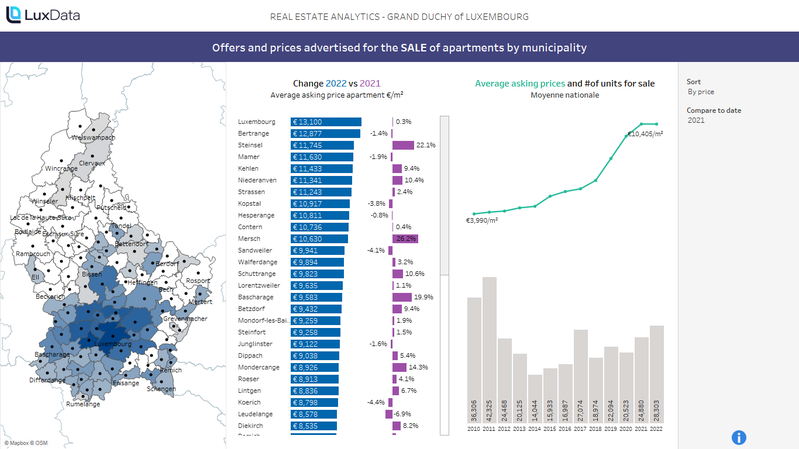
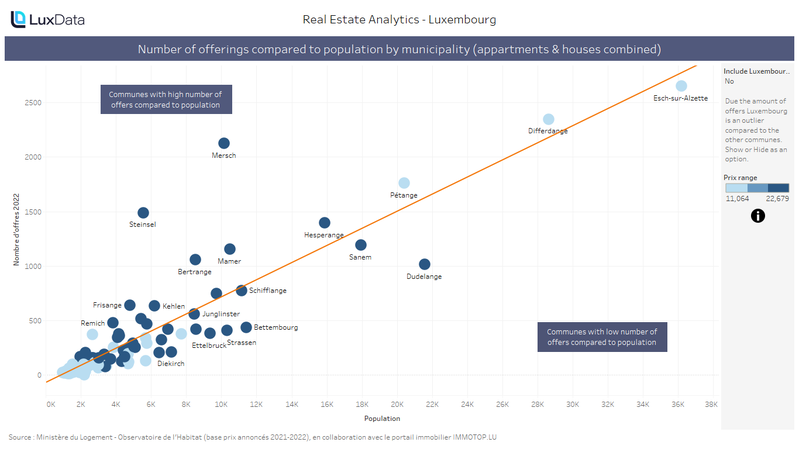
Real Estate Analytics Luxembourg - Offers and prices…
Visualisation
Publié le 19 avril 2024 par LuxData